Analyzing the potential of pre-trained embeddings for audio classification tasks
1. Detailed classification results
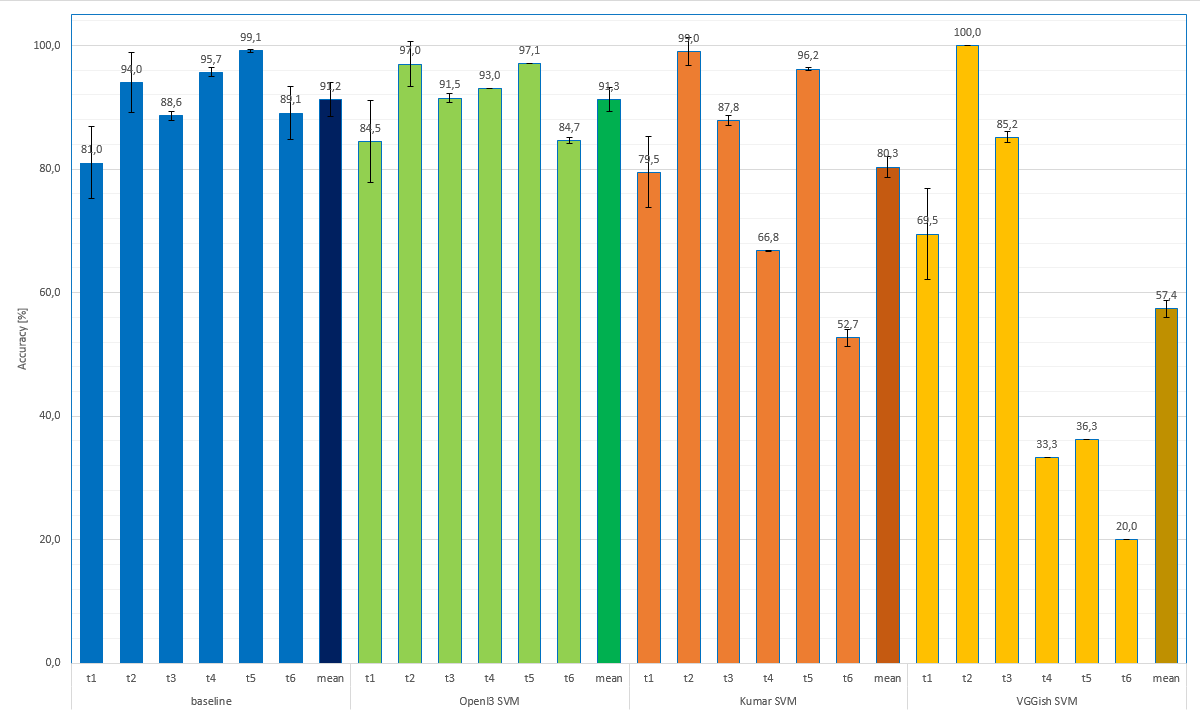
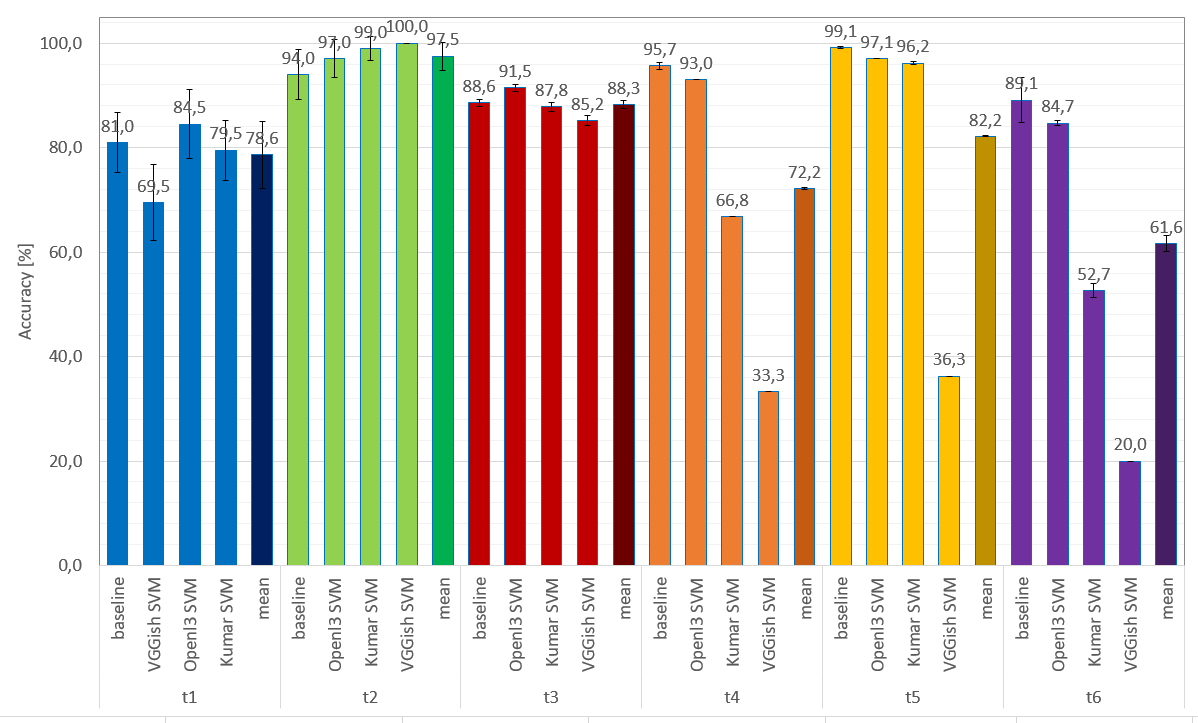
The following plot (a) shows the classification results for all experiments based on the (best performing) linear SVM classifier. An alternative ordernig can be seen in (b) where results of the same task are grouped together.
(a)
(b)
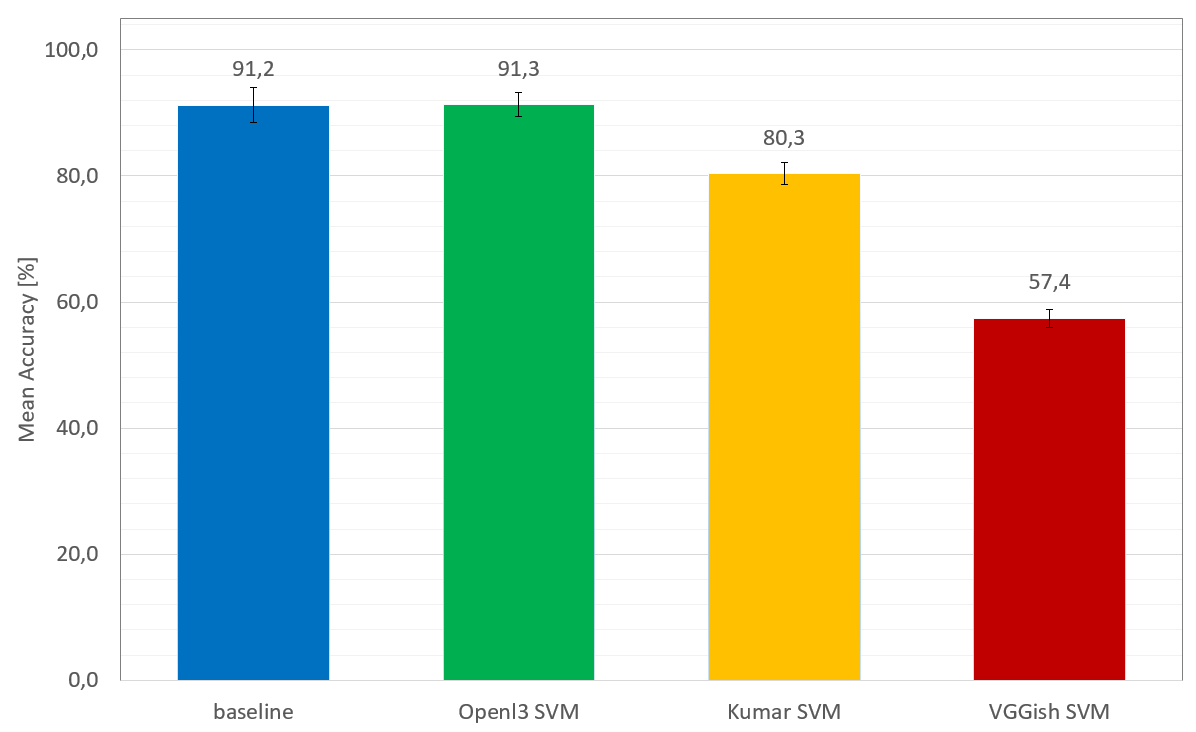
Overall average results for each embedding using linear SVM can be seen in the following figure. One can observe that OpenL3 embeddings outperform all other embeddings, and obtain comparable results to the baseline model:
2. Tables containing detailed results
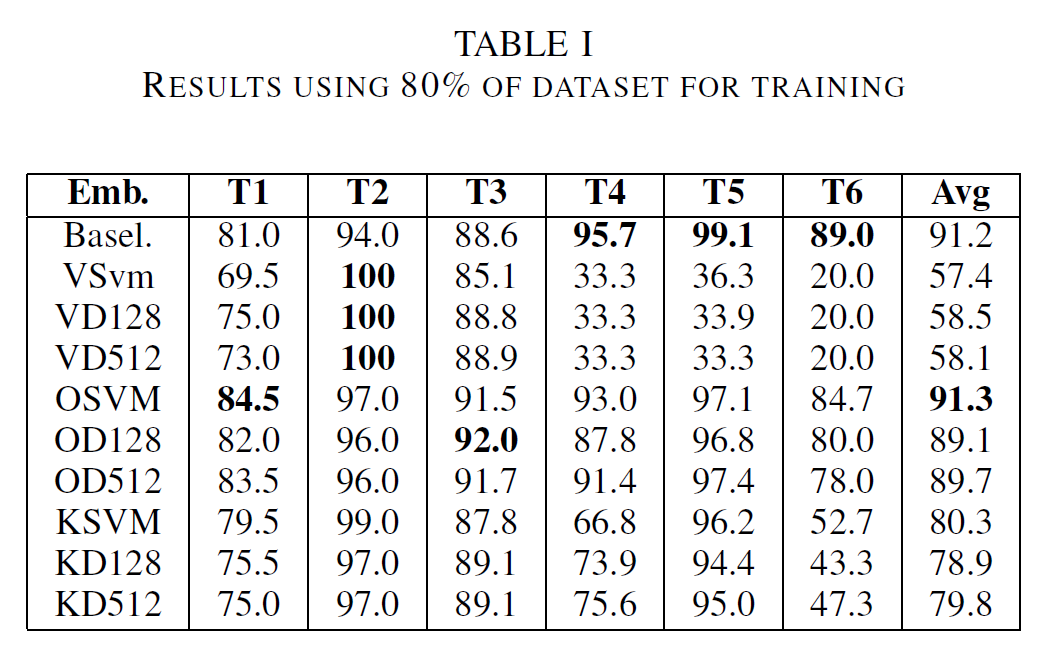
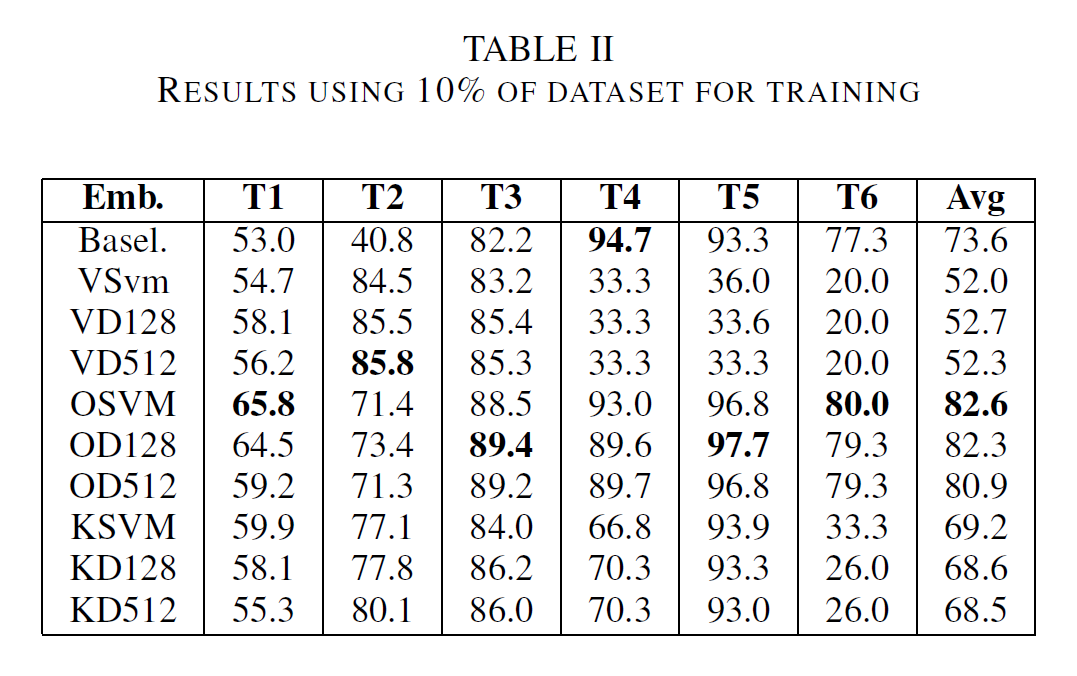
The following tables contain detailed results for each classifier-task combination. Table I shows results when using 80% of the dataset for training. To highlight the difference between embeddings and baseline models for small datasets, Table II displays the results using only 10% of the set for training. Here OpenL3 combined with a linear SVM outperforms the other embeddings as well as the baseline.
 |
 |
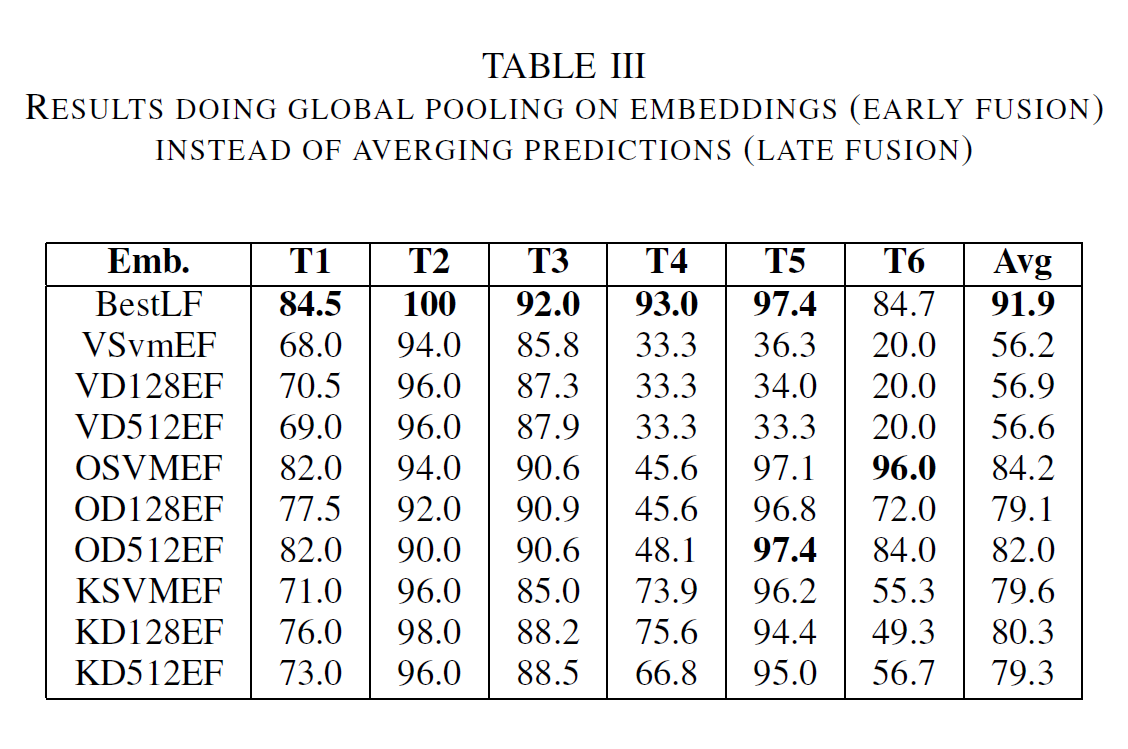
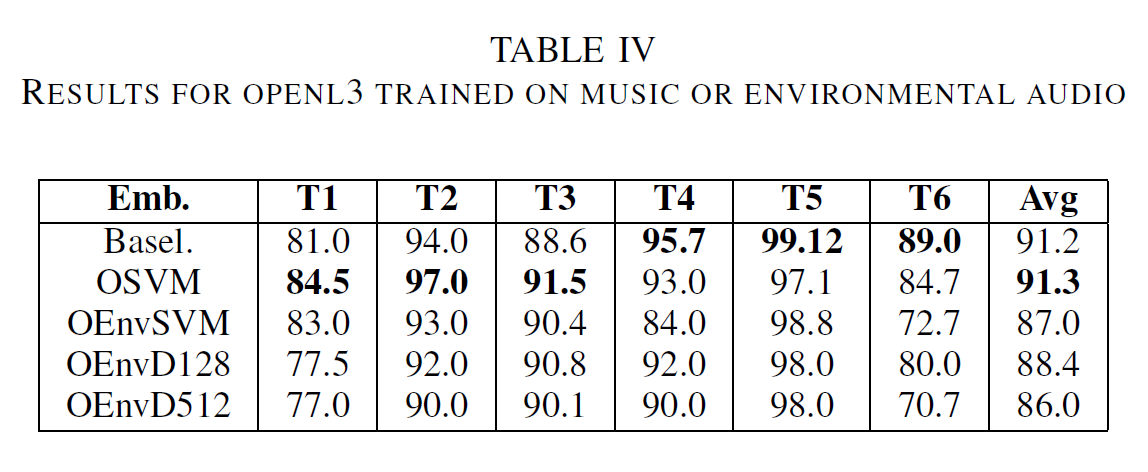
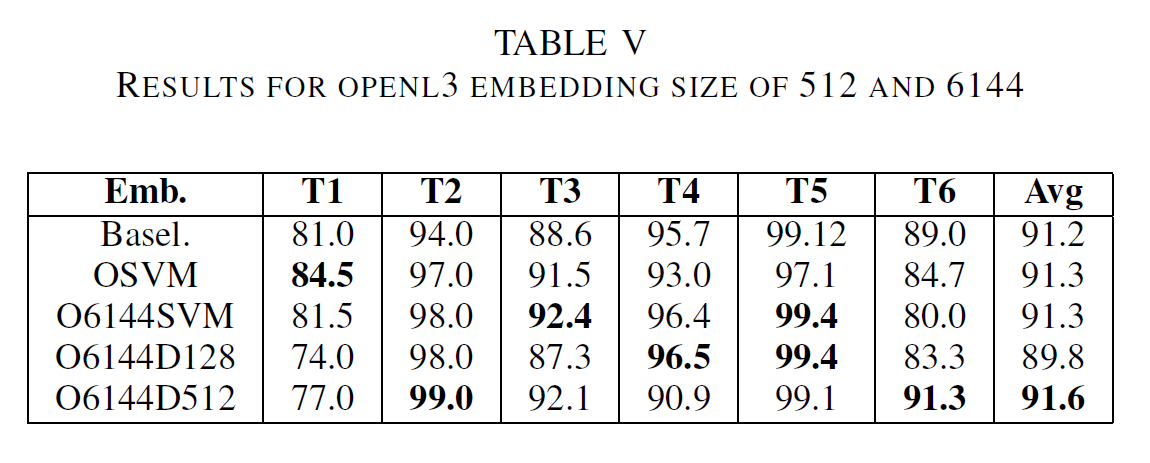
| Table III shows results comparing early fusion with late fusion approaches. Apart from task 6, late fusion performs best in all experiments. Table IV presents a comparison between different OpenL3 embeddings. Environmental embeddings perform constantly worse compared to the ones trained on music. Table V illustrates the results with OpenL3 embeddings with 512 values and larger embeddings with of 6144 values. Apart from Task 1, all tasks show better results with larger embeddings. However, larger embeddings are more computationally expensive. | |
 |
|
3. Confusion matrices
In this section, the confusion matrices with mean file-wise accuracy for all tasks are shown.
Task 1 - Ensemble Size Classification in Music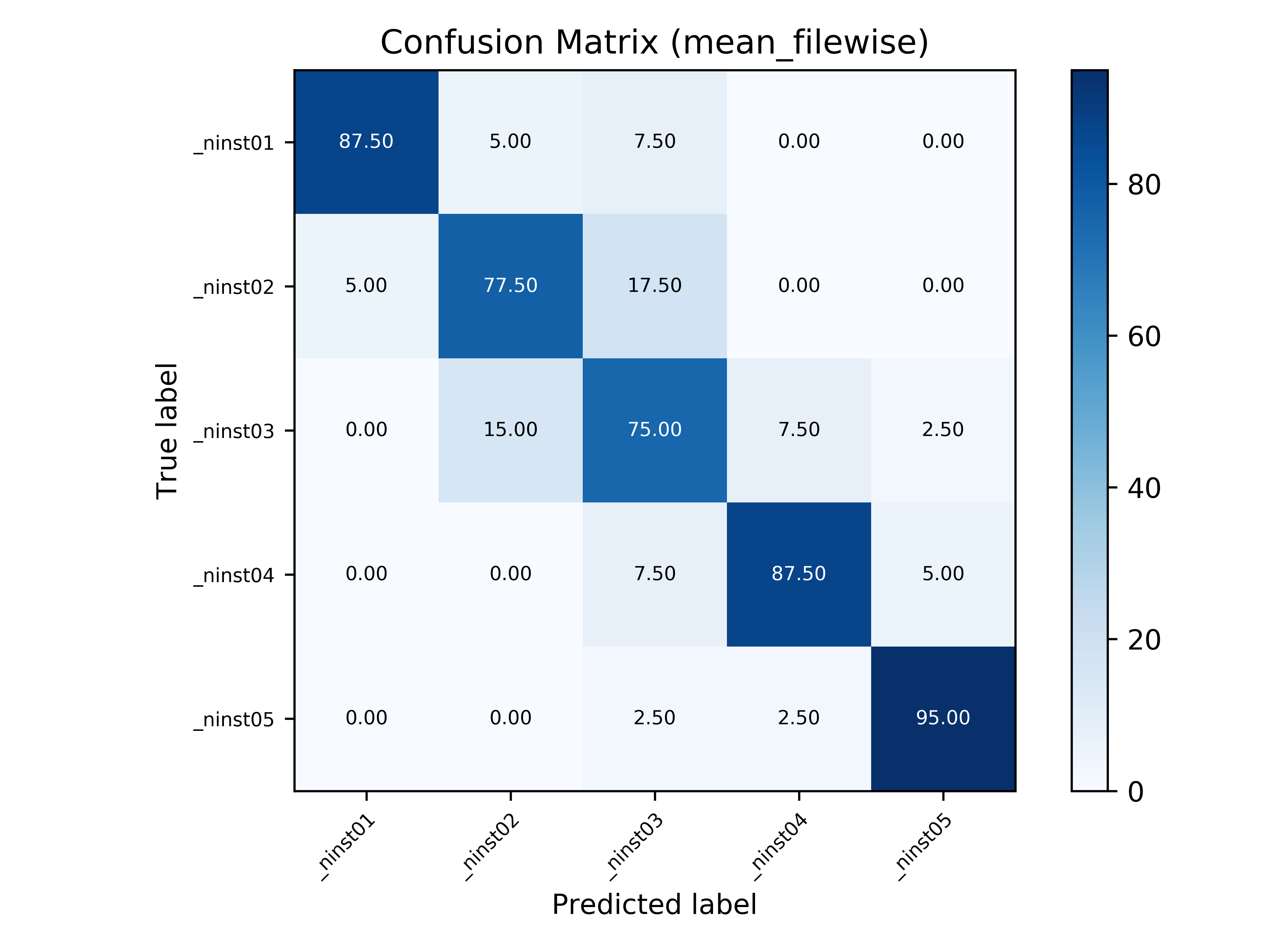 |
Task 2 - Musical Instrument Family Recognition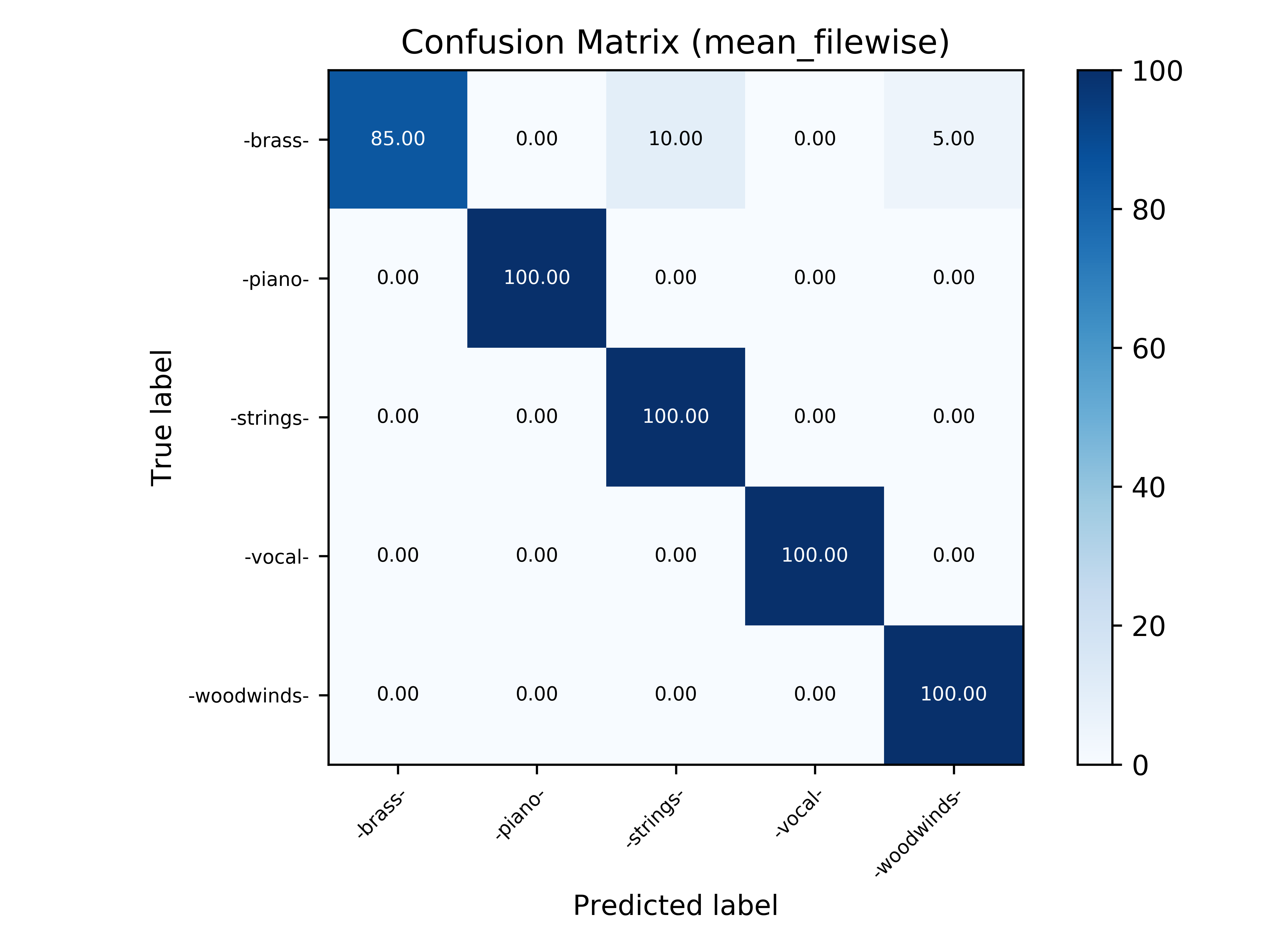 |
Task 3 - Speech Music Classification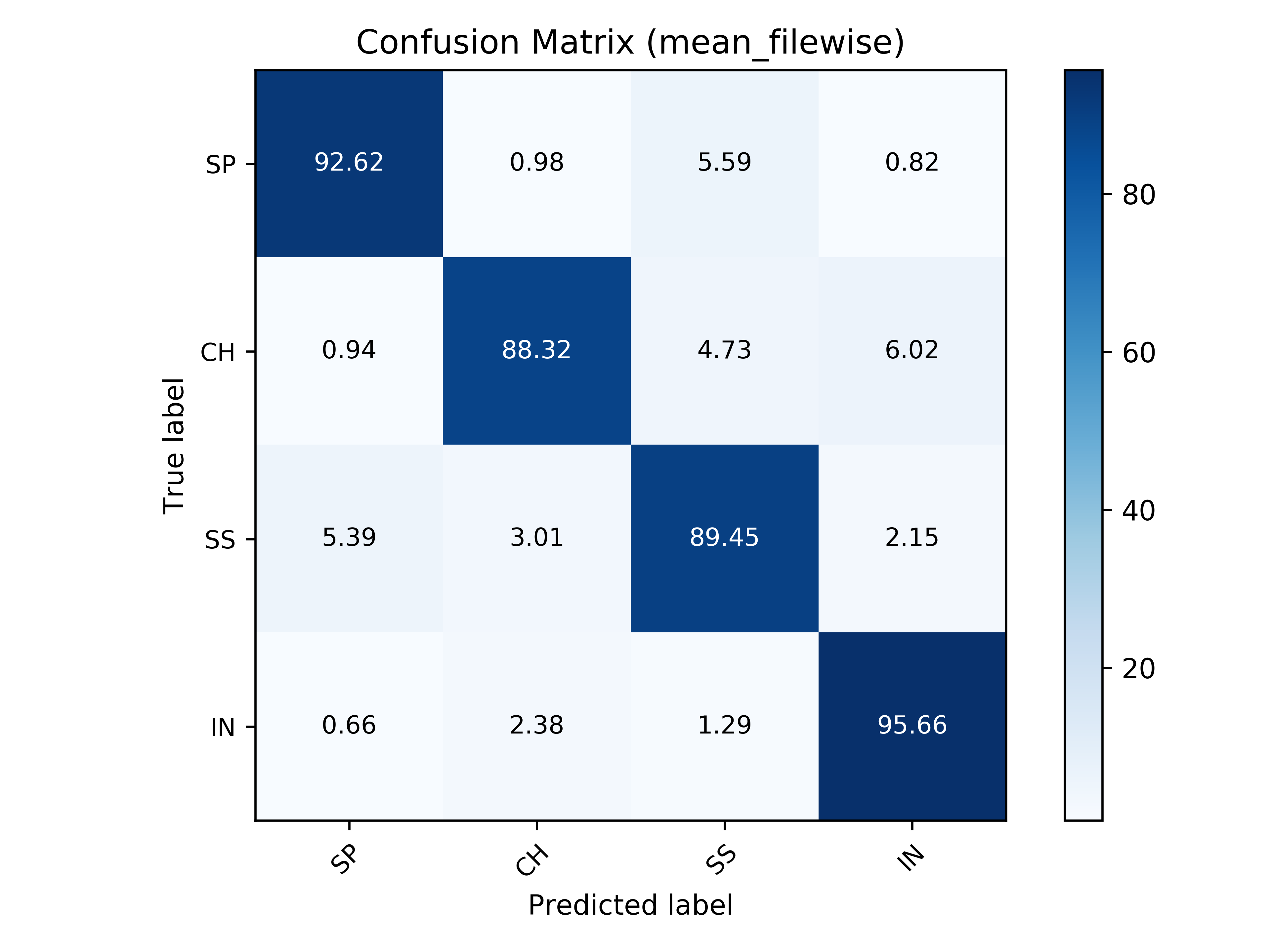
|
Task 4 - Classification of Operational States in Electric Engines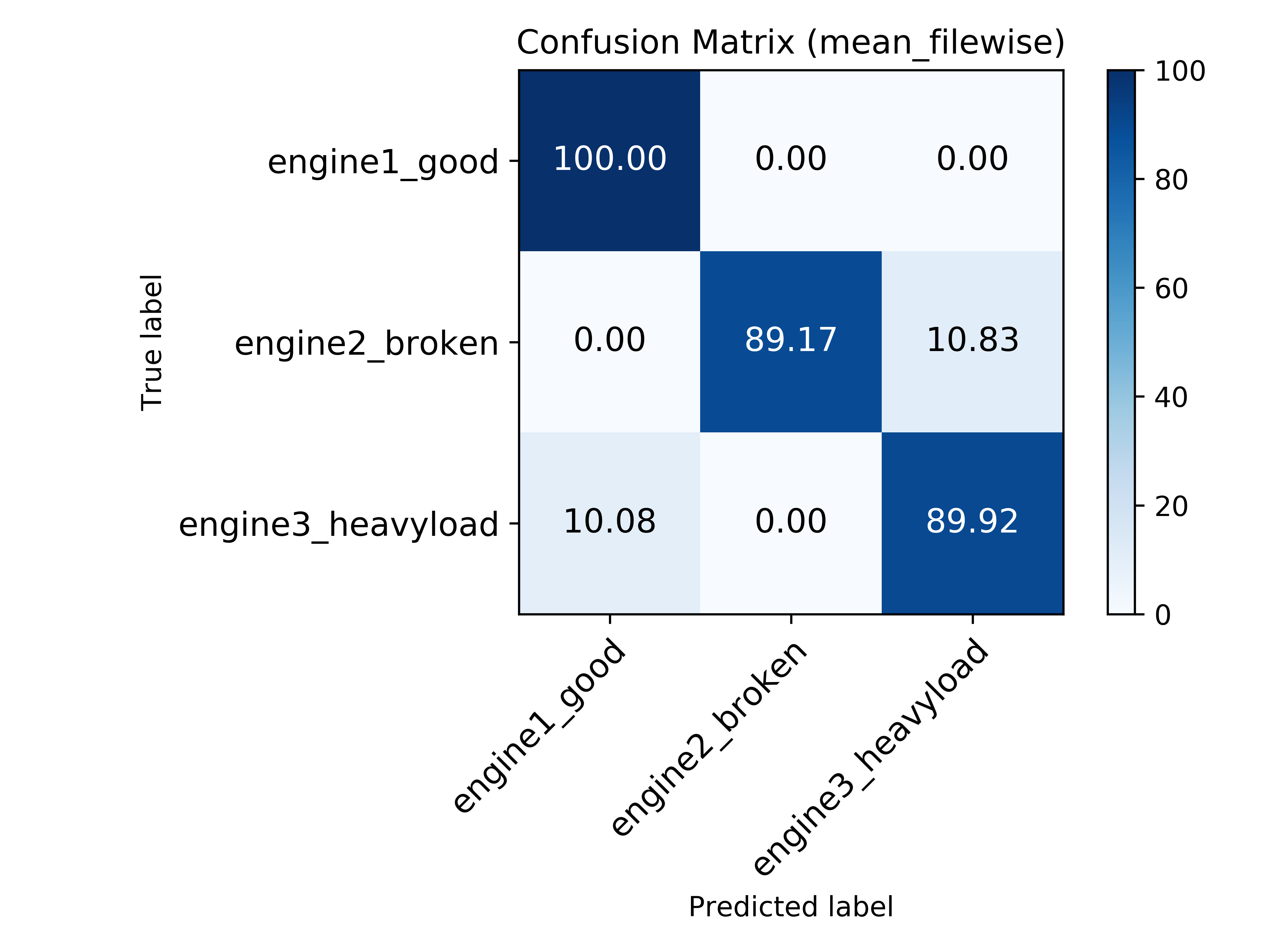 |
Task 5 - Metal Surface Classification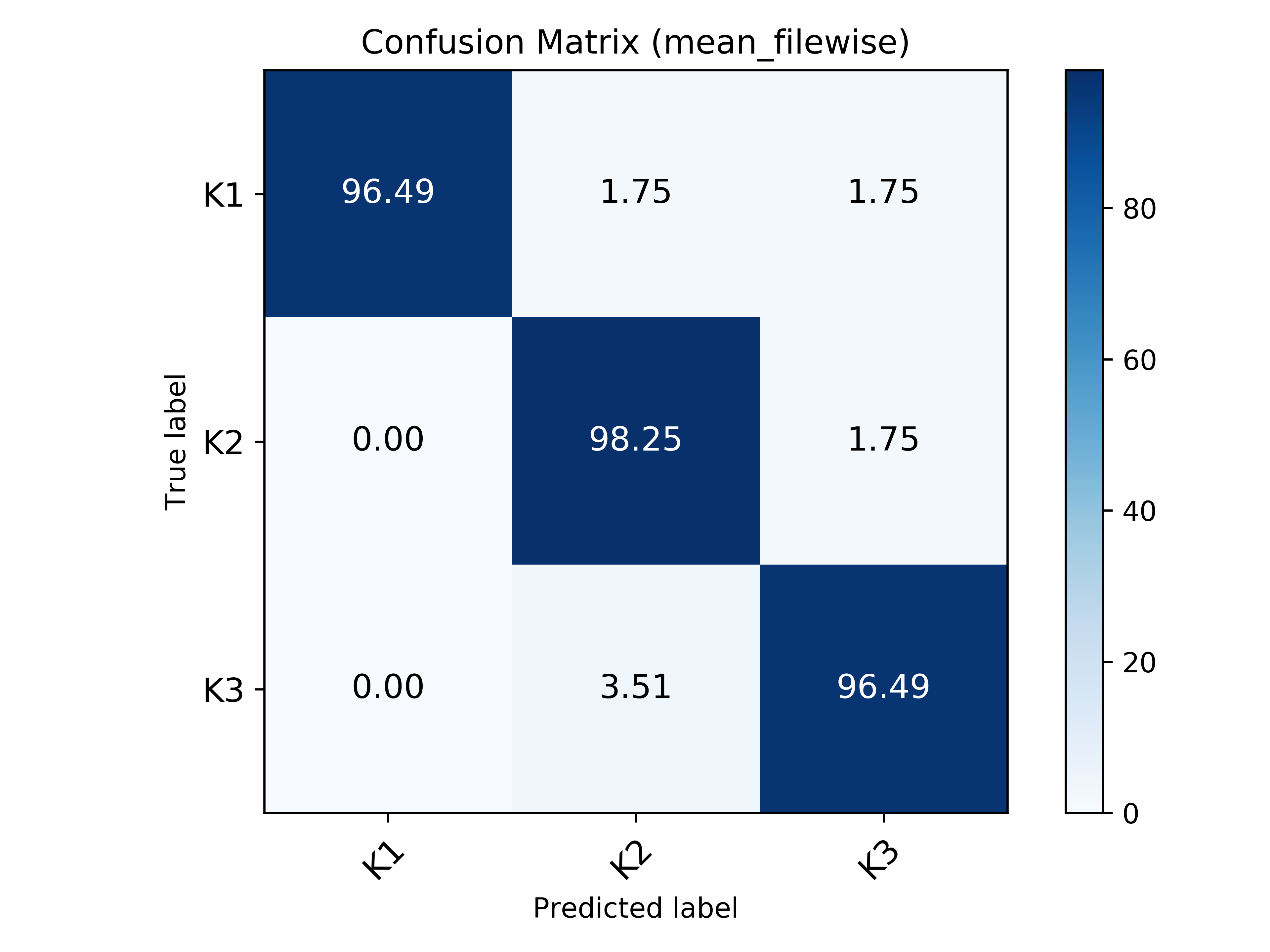 |
Task 6 - Plastic Material Classification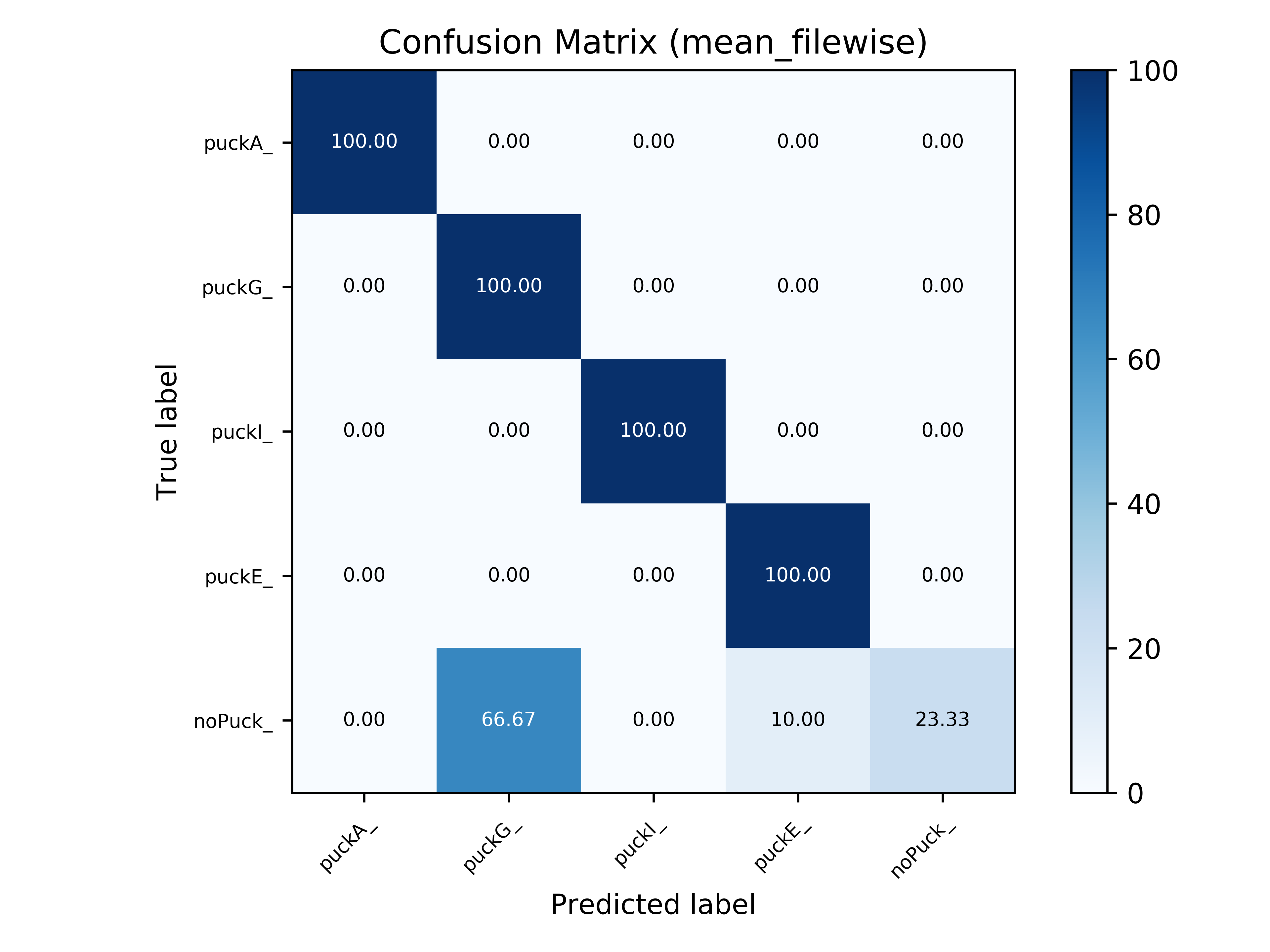 |
Task 6 - Plastic Material Classification (Early Fusion)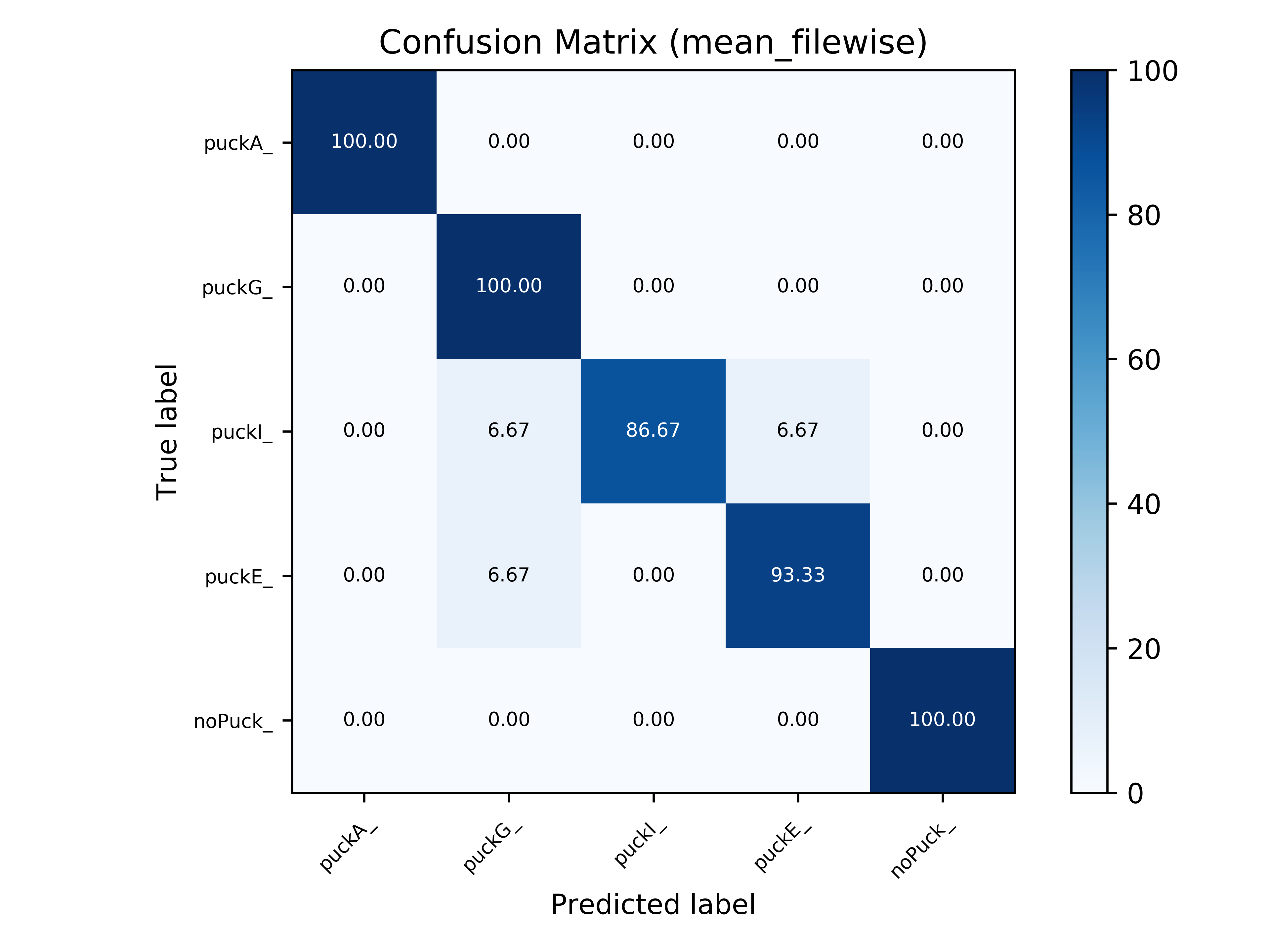 |
Task 6 - Plastic Material Classification (Late Fusion) |
4. Baseline models
Here the baseline model of task 2 (Musical Instrument Family Recognition) can be seen.
The first plot shows the actual model used for this publication. In contrast to the original model (below), each convolutional block has only half of the layers (two of the original four convolutional blocks have been removed). After each block, batch normalization is applied. Dropout has been moved to the end of the model to avoid overfitting. Finally, the Sigmoid activation has been replaced with a softmax activation in the output layer since the application is a single label task.
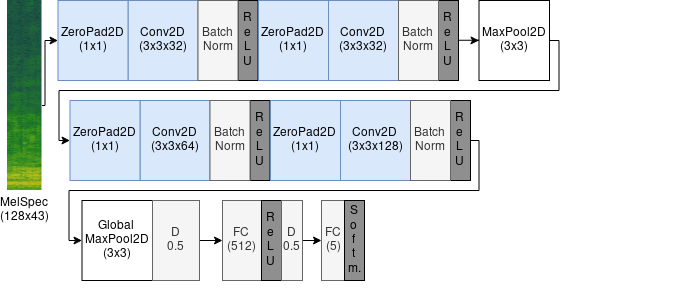
The plot below describes the original model from Han et. al Y. Han, J. Kim, and K. Lee, “Deep Convolutional Neural Networks for Predominant Instrument Recognition in Polyphonic Music,”IEEE/ACMTransactions on Audio, Speech, and Language Processing, vol. PP, 2016.
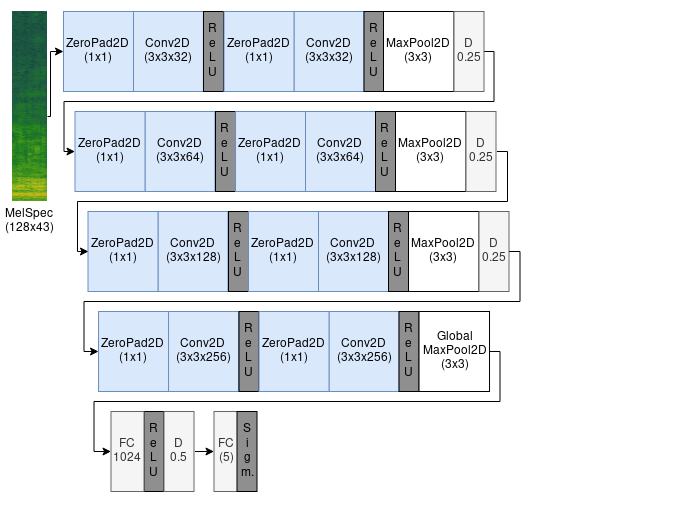
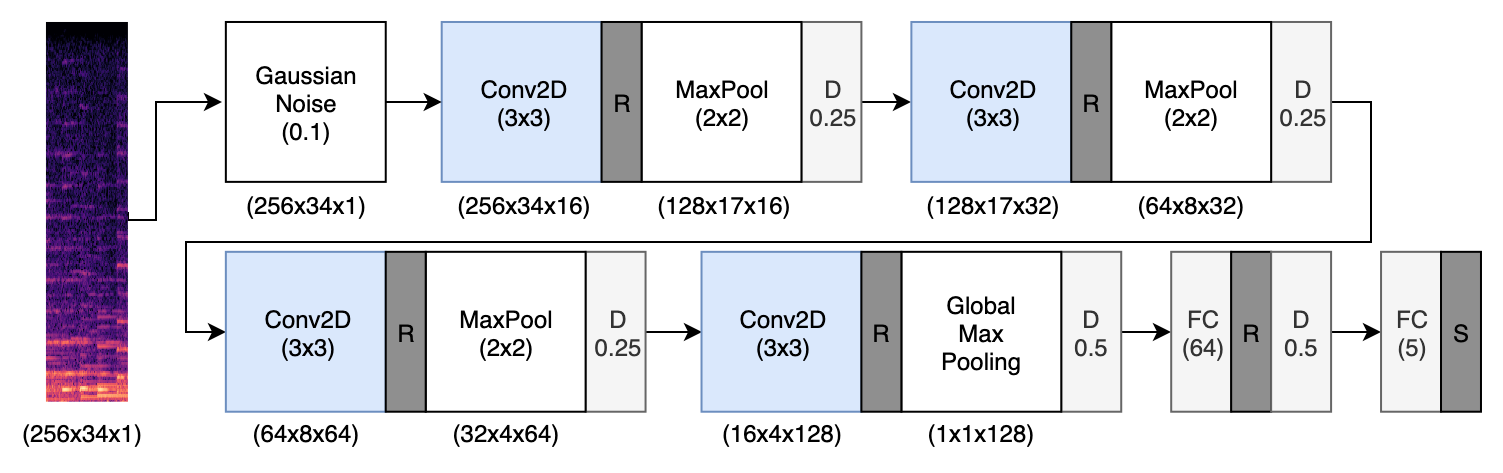
The following image shows the baseline model used for the Task 1 and Task 3. It is a CNN with 4 convolutional layers with a 3x3 kernel and a fully connected (dense) layer at the end. Max Pooling and dropout is applied after each block and a softmax activation is used for the output layer. The number of filters doubles in each convolutional block and starts with 16.